If you are serious about storing time series data, then you need to ensure you are storing that data in a way that is useful for your organization, not just today, but in the future as well. When data historians use data interpolation, the reliability of the data archive can be compromised.
What is data interpolation?
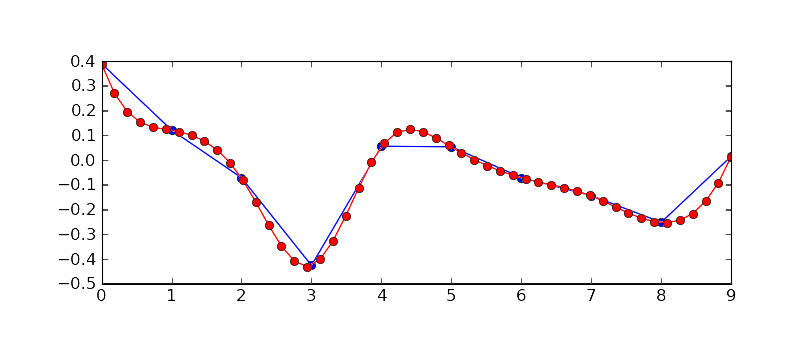
Data interpolation is an equation used to find missing values between two points on a line or curve. Historians make use of data interpolation in reverse. Rather than finding missing points, the goal is to reduce points deemed unnecessary on a line or curve. The goal is to keep the essence or 'feel' of the data without having to record all the data values. Types of data interpolation can vary, but all work to reduce the number of points written to the historical record. Below is an example of raw data, in blue, and the interpolated version of that data, in red. As you can see, the general 'feel' of the data is represented, but much of the detail has been lost. For some data, this is acceptable for immediate analysis. But what is the impact when that data is to be fed into a machine learning algorithm in the future? Would it be wise to keep all data in raw format if possible?
Why do historians do this?
All data historians have a problem they must solve, how to handle impossibly large data records while maintaining satisfactory write and retrieval speeds. Most historians have attempted to address this issue by working to reduce the overall size of the historical record; enter data interpolation. While this will help, it is not the best path. Instead, companies should be deploying data historians optimized and structured for the specific challenges that industrial automation time series data presents rather than settling for simply reducing the size of data archives through the trimming of the archive itself.
A conversation around data interpolation and historians can be confusing, especially when you consider that data interpolation can occur in one of three different areas, data collection, data storage, and data retrieval.
Interpolation during data collection.
Data collection, or data logging, is the process of mapping tags from devices in the field to tags within the data historian. Often this involves selecting tags from an OPC server or subscribing to MQTT topics.
During this process, you may be given an option on whether to obtain the entire record or an interpolated record of the tag in the historian. If possible you will always want to keep the data in raw format, meaning, every change of the data value will be archived. Often, this is not possible due to the limitations of the historian. When this is the case, you will be forced to choose a data interpolation storage method, meaning, you will store less data.
Choosing an interpolation storage method during the logging configuration results in one of two scenarios depending on the historian vendor. Scenario one would transmit all data changes and make them available for real-time viewing. Then, the system would interpolate the data and store only the interpolated points as part of the historical archive.
However, some solutions may choose to apply data interpolation at the edge and only transmit the interpolated data rather than the raw data values, meaning you will never have access to the raw values, even in real-time.
Keep in mind data interpolation and deadbanding are not the same thing. Deadbanding is used to set specific condition-based rules on when to log data. These rules can be based on rate of change, time interval, percent of change, or other factors. For instance, if a value does not change by more than 0.1% it may be ignored. Deadbands are very useful to reduce instrumentation noise and do not require data interpolation.
Canary does not interpolate data during collection but does respect deadbands. Raw data values are preserved throughout the data collection process and are communicated to the historian. Bandwidth usage is minimized and whenever possible, Canary data collectors will only communicate tag values upon change while still updating time stamps.
Interpolation during data storage.
Often data historians are not able to compress data that has been collected unless they use some type of data interpolation. While vendors may use different interpolative algorithms (swing door, boxcar, data averaging, etc) all have one thing in common; you loose data. This is always a bad thing... so why do it when data storage is incredibly inexpensive?
Simply put, interpolating data is compensation for database performance, not a best practice. You can see this mentioned at the very beginning of the OSIsoft tutorial video below.
In this video, former OSIsoft staff (now AVEVA) address how PI interpolates data at collection and during storage with an explanation of how and why OSIsoft uses data interpolation.
Data interpolation always adversely effects data reliability. In their paper, Data Compression Issues with Pattern Matching in Historical Data, Singhal and Seborg examine the available data compression algorithms including PI's proprietary solution. Their findings rank PI as a top algorithm but still remark...
Although the PI algorithm produces a very low MSE [mean squared error], it does not represent the data very well for pattern matching.
But Pi is not alone in proprietary historians that use interpolation as a means of data compression. Wonderware and GE both use similar methodology.
When a data historian has not been optimized to handle trillions of potential historical inserts, performance will suffer for either writing new records, reading existing records, or both. The number of development hours required to solve these issues often force the hand of the historian vendor to follow the path most traveled, reduce the overall size of the database.
For instance, here is how GE handles the data storage problem with their historian.
Archive compression can result in fewer raw samples stored to disk than were sent by collector.If all samples are stored, the required storage space cannot be reduced. If we can safely discard any samples, then some storage space can be reduced. Briefly, points along a straight or linearly sloping line can be safely dropped without information loss to the user. The dropped points can be reconstructed by linear interpolation during data retrieval. The user will still retrieve real-world values, even though fewer points were stored.
Ultimately, most historian vendors force you to choose between performance limits or archived value limits. While fewer stored data points may indeed tell a similar story they never tell the whole story. This becomes extremely problematic when the data in question is to be used for machine learning. Providing machine learning models fewer data points and less granularity can negatively effect the outcome.
Canary decided long ago that this was not an acceptable option. The Canary Historian has been designed to store raw data values with a loss-less compression solution. That means once we write data to the historian, we can then compress that data (with a 65% compression algorithm) while never interpolating the data! This is truly a best-in-class offering and is the results of thousands of man hours spent over three decades.
Data interpolation upon retrieval.
The final area of interpolation to examine is on the retrieval of data. Once data is archived, historians allow clients to access that data on demand. These requests are made to the historian, the corresponding data is then retrieved and published to the client. There are both benefits and risks in using data interpolation for the retrieval of time series data.
One of the largest benefits is in the area of bandwidth and performance. As you might reason, the less data that has to move from historian to client will lead to higher recall performance and lower bandwidth consumption. Often clients may ask for very large sets of data. Interpolation can be used to greatly reduce the amount of data that needs sent, increase performance while limiting bandwidth.
However, interpolation can also negatively impact the client, especially if the interpolated data does not adequately represent the original sample. Solutions that allow the client to choose what type of data they wish to recall are ideal. This means, if the data exists in the historian in its original and raw format, the client making the request can designate whether to import the data in raw or processed (interpolated) format.
The Canary Historian stores all data in its original raw format with loss-less compression. However, the client can choose between retrieving data in either raw or processed configuration. This means you can choose to have all of the data published, or samples of data based on over 30 different aggregates including interpolation using sloped interpolation, time averaging, first/last value based on time period, and more.
Summary.
Canary firmly believes that data interpolation should not be used in collecting or storing industrial time series data. If the data historian technology is properly engineered, a system should be capable of collecting, sending, and storing data using minimal bandwidth with loss-less data compression. Data interpolation should be made available for the retrieval of data but needs to at the discretion of the client.



