
"What type of disk space will the Canary Historian need?" is a common question (and a valid one!) but not necessarily as simple as it might sound....

Data historians are key to an organization understanding their process, but some clients are worried about purchasing data historians due to cost. This guide will price popular historian options like AVEVA PI, Canary, and Ignition by Inductive Automation. Decide which data historian price is the best value.
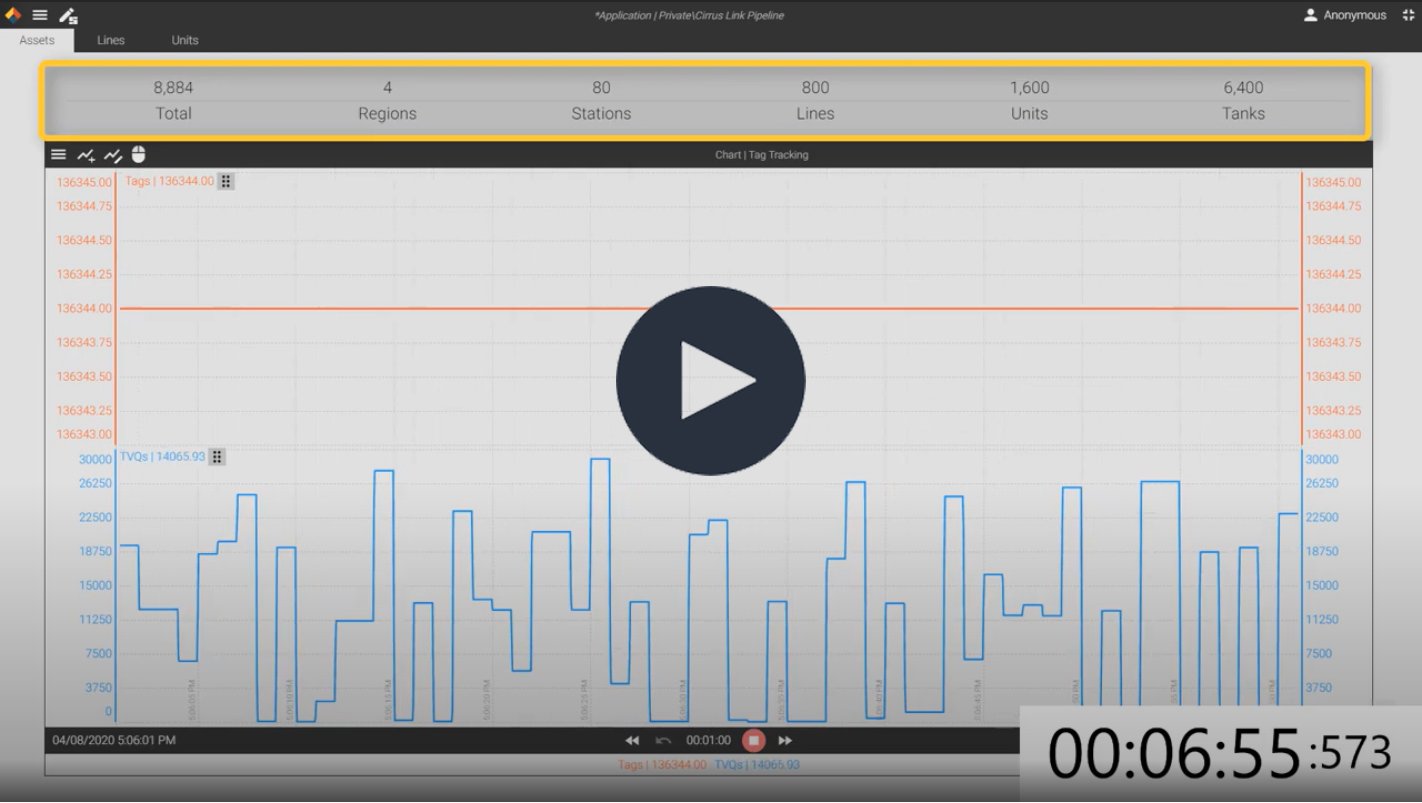
Some organizations constantly add new tags and assets to their operation. If this is true for you, it is likely you or your team are spending too much time manually adding tags and assigning them to your asset model.
Watch the video below to see how easy it could be!

More than ever, companies are understanding the importance, and necessity, of the data historian. With so many database options available to you, it can be a bit confusing to work through your options. This guide should make it easier to understand the choices you have when selecting a data historian for your industrial application.

Some companies deal with an ever changing landscape of devices and tags. Whether it be assets in the field, or entire plants that come online, if you can automate the discovery of new tags and assets you will dramatically decrease your workload while providing faster data access to your client tools.
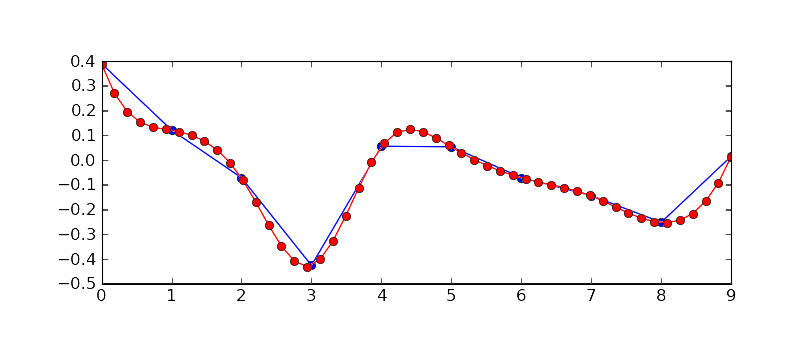
If you are serious about storing time series data, then you need to ensure you are storing that data in a way that is useful for your organization, not just today, but in the future as well. When data historians use data interpolation, the reliability of the data archive can be compromised.
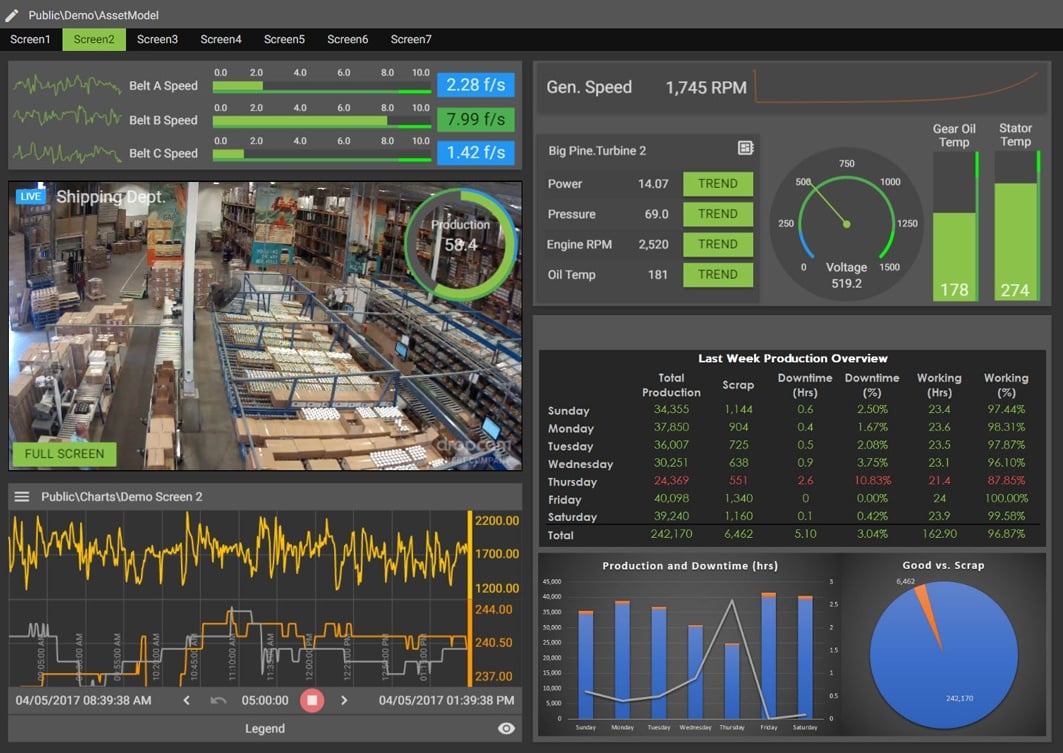
Battling inefficiencies and trying to save money is important to every industrial process. It is frustrating that most companies first have to invest a large amount of capital to equip themselves with SCADA solutions and data historians in order to find ways to run more efficiently.
Recently, Murphy Oil independently published an article in "Data Science and Digital Engineering for Upstream Oil and Gas". That article, Murphy Oil Maximizes Operations With Canary, details their journey to find an industrial database that would deliver the tools their operations needed to become more efficient.

For redundancy, it is recommended you push data from the Canary Collecter and Sender Service to both a primary and secondary Historian’s Receiver Services. This means that both the primary and secondary Historian are getting the same constant data feed from any Canary Collector.
Could Cassandra be optimized to store time-series data? This is a question that has become a common topic for discussion. I recently came across a great read that compares Cassandra performance to another dedicated time-series database, TimescaleDB.


